Introduction
Below I’ve collected some information for what I think is a serious Elastic SIEM setup. I would like to share the train of thought behind this design and would appreciate any feedback. Namely in terms of scalability and hardware requirements and utilization. I’m also in particular interested how others distribute the network load over multiple systems. I’m looking at the moment at this appliance.
Related work
A packet broker solution is discussed in this LRZ presentation to distribute the load over multiple nodes.
Preliminary results
- Current hardware can handle 20+ Gbps without any problems – even without bypass or shunting of „elephant flows“
- Commodity hardware can achieve 40Gbps, with dedicated NIC and shunting, even more.
- If you use the NIC only for Suricata, buy a cheaper NIC and invest the money into more cores (SEPTun recommendation) still true up to 40Gbps. At 100Gbps it will a be different story
- 100Gbps in a Single Server is still difficult – bypass / filter required
- NUMA Node placement is important
- PCIe Bottleneck at 100Gbps – again, bypass / filter required
- 2x 40Gbps on Dual CPU should be possible on commodity hardware
In this related work the following points are discussed and summarized below.
RSS
Researchers in the related work used an Intel 82599ES 10-Gigabit/x520/x540 for RSS symmetric hashing on the NIC.
It [RSS] does a general load balancing of network data over multiple cores or CPUs by using IP tuple to calculate a hash value. The problem from the IDS/IPS perspective is that it needs to see the traffic as the end client will to do its job correctly. The challenge with RSS is that it RSS has been made for another purpose for example scaling of large web/filesharing installations and thus not needing the same “flow” consistency as an IDS/IPS deployment. As explained clearly in the Suricata documentation:
“Receive Side Scaling is a technique used by network cards to distribute incoming
traffic over various queues on the NIC. This is meant to improve performance, but it is important to realize that it was designed for average traffic, not for the IDS packet capture scenario. RSS using a hash algorithm to distribute the incoming traffic over the various queues. This hash is normally not symmetrical. This means that when receiving both sides of flow, each side may end up in a different queue. Sadly, when deploying Suricata, this is the typical scenario when using span ports or taps. “
More information about RSS by Intel in this white paper.

CPU affinity
Make sure irqbalance is disabled. Pin interrupts to the CPUs on a NUMA node, same as the card. Use CPU affinity with Suricata (suricata.yaml) and make sure the af-packet worker threads are running on anything but NUMA 0 in case that one is used (see related work for more details).
In case of no RSS symmetric hashing available you can try xdp_cpumap Make sure
you are sitting on Linux kernel 4.15.+
- use xdp-cpu-redirect: [xx-xx] (af_packet section of suriata.yaml)
- use cluster-type: cluster_cpu (af_packet section of suriata.yaml)
- make sure you pin all interrupts of the NIC to one CPU (make sure it is on the
same NUMA as on the NIC) - have CPU affinity enabled and used on the cores of the appropriate NUMA node
wise for the NIC location cores.
XDP
XDP or eXpress Data Path provides a high performance, programmable network data path in the Linux kernel as part of the IO Visor Project. XDP provides bare metal packet processing at the lowest point in the software stack which makes it ideal for speed without compromising programmability. Furthermore, new functions can be implemented dynamically with the integrated fast path without kernel modification. Source.
XDP provides a serious performance boost for native Linux drivers by introducing the XDP bypass functionality to Suricata which in turn allows for dealing with elephant flows much earlier in the critical packet path. Thus offloading significant work from Suricata and the kernel regarding the capability to bypass 15 flows before Suricata process them - minimizing the perf intensive work needed to be done.
Intel NIC interrupt bugs
One of the most critical bugs as of the moment of writing this article is the IRQs reset one (on some kernel version/ Intel NIC combo). It seems right after Suricata starts and the eBPF script code gets injected all interrupts are pinned to CPU0 (and we need them to be spread - not like that.)
To counter the problem above (and the case of no symmetric RSS availability) in a more permanent basis - the xdp_cpumap concept code was ported and introduced into Suricata by Eric Leblond in January 2018. The xdp_cpumap is a recent Linux kernel xdp feature that (among other things) enables redirection XDP frames to remote CPUs (page 13) without breaking the flow.
Filtering (shunting)
No need to waste CPU resources on Netflix streams or encrypted traffic, this may be filtered out. XDP allows us to drop packets at various stages:
- On the NIC directly (requires compatible hardware, best option)
- At driver level (requires XDP compatible driver)
- At kernel level (fallback, slowest option)
Hardware requirements
- Some more details concerning tuning of NICs and CPU resources: 11.5. High Performance Configuration — Suricata 9.0.0-dev documentation
- Elastic hardware requirements: Hardware prerequisites | Elastic Docs
Buildup phases
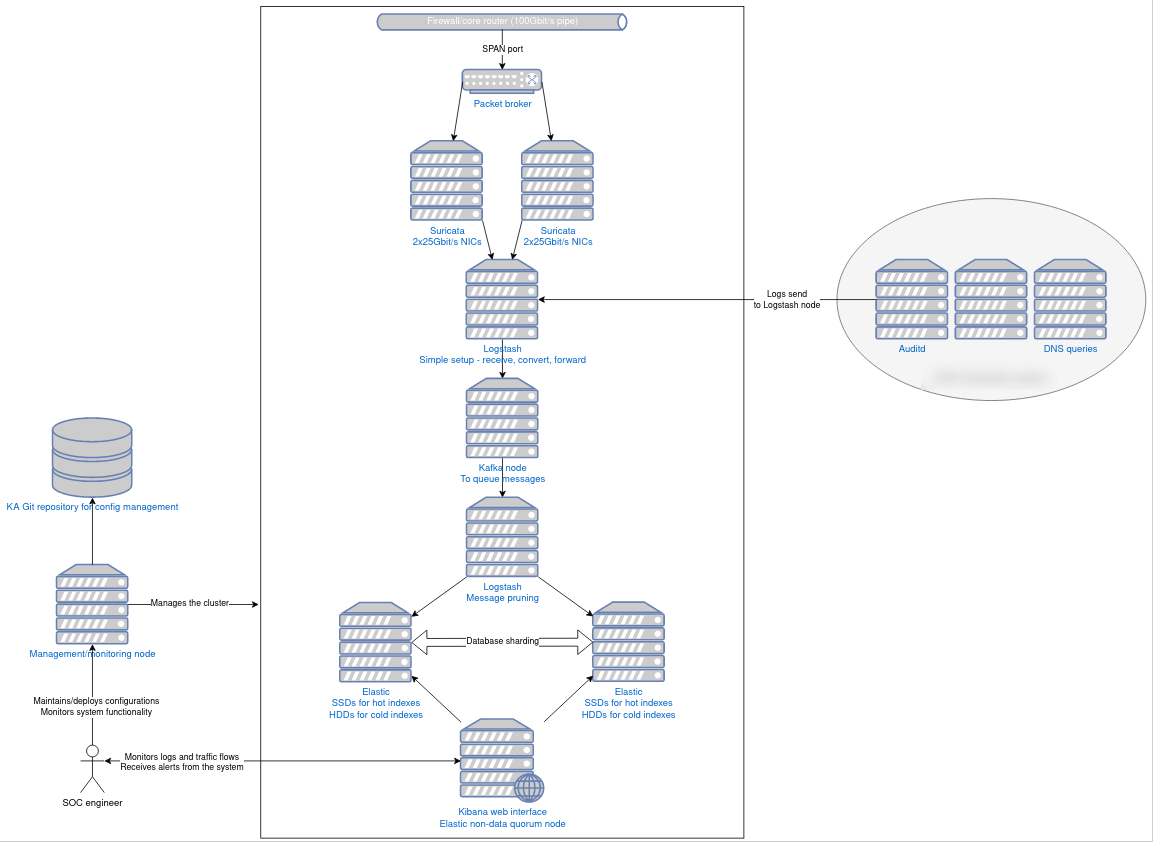
To slowly get a feeling of the hardware and needed performance, it would be great to gradually expose the cluster to network and log loads. With that strategy we can also add hardware in phases and see how well the horizontal scaling is going.
Phase 1
- Packet broker
- 1x Suricata node with 2x 25Gbit/s NICs, where each CPU is pinned to a NIC
- 1x Logstash node
- 1x Elastic node (which also hosts the Kibana web interface)
Phase 2.. 3… 4…
- Add more Suricata nodes when the bandwidth reaches the maximum (benchmark if 25Gbit/s is even possible per NIC)
- Once the single Logstash node starts to have performance issues, add another Logstash node, which uses a Kafka node in between to store and forward messages to the primary Logstash node, which then stores data into Elastic
- Once performance starts to throttle in Elastic, add another node
- Have a dedicated Kibana node, which also acts as a non-data quorum node for the Elastic nodes